The following database rules explain the usage of the database called oedb, which will become a part of the openmod internet presence. For further details see also here.
Data Documentation
- All data included in the databases has be documented! On this wiki page you learn, how to do so.
- All abreviations have to be documentated in the
Naming of Data
The data in the database is organised in schemata and tables, which names are important to find around.
Database Name
The name of the database is oedb.
Database Schema
The structure of the database is realised via the naming of the schemata, which follows the following rules:
- always lower case
- no points, no commas
- no spaces
- no dates
- use underscores
- The name starts with the type of the schema:
- orig for original data: Data that is directly available in other sources and underwent no editing other than transfering it to a data base friendly format
- calc for processed data: Data that origin from original data or processed data via some script or other modifications. The specific data and methods used for this computations must be mentioned.
- res for result data: Data that is the result of an energy model
- The name includes the distinct subject area or source.
Example: orig_vg250
Database Table
- always lower case
- no points, no commas
- no spaces
- no dates
- use underscores
The table name consists of
- name starts with the source (e.g. zensus)
- main value (e.g. population)
- if separated by [attribute] (e.g. by_gender)
- with resolution [tupel] (e.g. per_mun)
Example: zensus_population_by_gender_per_mun
Data Integrity
"Data integrity refers to maintaining and assuring the accuracy and consistency of data over its entire life-cycle." (Wikipedia) These two aspects belong to the data quality criteria, the data in the oedb should meet.
Data Integrity is one aspect of ensuring data quality the in the oedb.
General
- Each table should have a single auto-incremented integer column as Primary Key with the corresponding table constraint.
- Grant all privilegs to oeuser (automatically done by the system)
Geografic Data
- WGS84 - EPSG: 4326 (http://spatialreference.org/ref/epsg/4326/)
- ETRS89 / ETRS-LAEA - EPSG: 3035 (http://spatialreference.org/ref/epsg/3035/)
Data Referencing
There are several useful attributes on a table users have to know in order to work with the contained data efficiently. Therefore, ensuring the quality of these meta data is as important as ensuring the quality of the data itself (see also here).
For these meta data the documentation open-standard Json is used (Wiki and Json.org). The documentation is separated in two major categories:
- Comments on schema: Contains metadata that define several aspects for the database schema
- Comments on tables: Contains metadata that define several aspects for the whole table
- Comments on rows: Store important informations on a specific row and the stored data
Schemata are used in the database in order to structure tables, functions, assign assignment of permissions and much more. For the documentation purpose a string in json format is set as comment on schema. The attribute names begins with an upper case and are given by the following definition for schemata.
Metadata Documentation of schemata
| Attribute (level 1)
|
Attribute (level 2)
|
Description
|
| Name
|
|
Original name of the data set
|
| Description
|
|
Short description of the data set.
|
| Changes
|
|
Information of changes and user
|
|
|
Name
|
Name of Person created or changed dataset
|
| Mail
|
E-mail Address
|
| Date
|
Date of changes
|
| Comment
|
Comment of changes
|
| Note
|
|
Field for notes or ToDo which are not done yet
|
SQL Json Example
Comments on a table are json-dictionary as strings that describe the overall structure of the corresponding table. For every field the corresponding unit (in case of numerical values) and a description that specifies the contained data should be attached. The attribute names begins with an upper case and are given by the following definition of Database Tables. The Json meta documentation string is stored as table comment on the database table.
Original Data (orig)
Original Data (orig) are defined as data from one source which are not further processed (see: Database Schema). The metadata Documentation for those data sets are set as a comment on the table. Following meta data are proposed:
Metadata Documentation of original data on table
| Attribute (level 1)
|
Attribute (level 2)
|
Description
|
| Name
|
|
Original name of the data set
|
| Source
|
|
|
|
|
Name
|
Source Name
|
| URL
|
URL string
|
| Reference date
|
|
Reference date of the data set.
|
| Date of collection
|
|
Date of data collection into the database.
|
| Original file
|
|
Name of the original data file with file extension (e.g. .xls,.shp, .pdf, etc.)
|
| Spatial resolution
|
|
Spatial resolution of the data set
|
| Description
|
|
Short description of the data set.
|
| Column
|
|
Metadata of all table fields / columns
|
|
|
Name
|
Name of Column 1
|
| Description
|
English description of Column 1
|
| Unit
|
Unit if exist e.g. (€, MWh, etc.)
|
|
|
…
|
...
|
|
|
Name
|
Name of Column N
|
| Description
|
English description of Column N
|
| Unit
|
Unit if exist e.g. (€, MWh, etc.)
|
| Changes
|
|
Information of changes and user
|
|
|
Name
|
Name of Person created or changed dataset
|
| Mail
|
E-mail Address
|
| Date
|
Date of changes
|
| Comment
|
Comment of changes
|
| ToDo
|
|
Comment of ToDo which are not done yet
|
| Licence
|
|
Licence of the data set
|
|
Name
|
Name of Licence
|
|
|
URL
|
URL of Licence
|
| Instructions for proper use
|
|
Instructions for proper use of Licences.
|
Json Example:
{
"Name": "Original name of the data set",
"Source":[{
"Name": "Website of data",
"URL": "www.website.com" }],
"Reference date": ["2013"],
"Date of collection": ["01.08.2013"],
"Original file": ["346-22-5.xls"],
"Spatial resolution": ["Germany"],
"Description": ["Example Data (annual totals)", "Regional level: national"],
"Column": [
{"Name":"id",
"Description":"Unique identifier",
"Unit":"" },
{"Name":"year",
"Description":"Reference Year",
"Unit":"" },
{"Name":"example_value",
"Description": "Some important value",
"Unit":"EUR" }],
"Changes":[
{"Name":"Joe Nobody",
"Mail":"joe.nobody@gmail.com (fake)",
"Date":"16.06.2014",
"Comment":"Created table" },
{"Name":"Joana Anybody",
"Mail":"joana.anybody@gmail.com (fake)",
"Date":"17.07.2014",
"Comment":"Translated field names"}],
"Note": ["Some datasets are odd -> Check numbers against another data"],
"Licence": [{"Name":"Licence – Version 2.0 (dl-de/by-2-0",
"URL": "http://www.govdata.de/dl-de/by-2-0]"],
"Instructions for proper use": ["Always state licence"]
}
|
Meta Documentation of original data collections from several sources:
In addition to the meta documentation described above, data tables (blue table in figure) which include data from several sources get a ref_id column. The ref_id links each row with a json documentation string (ref_data_json) in the database table public.reference_to_entries (green table in figure).This table also includes the ref_data_json column which links to all sources of the row to be referenced (blue). The ref_data_json string includes one jabref_entries_id for each source used. The jabref_entries_id is matched by one entries_id belonging to a source stored in the public.entries table (orange table).
Example: ER-Model
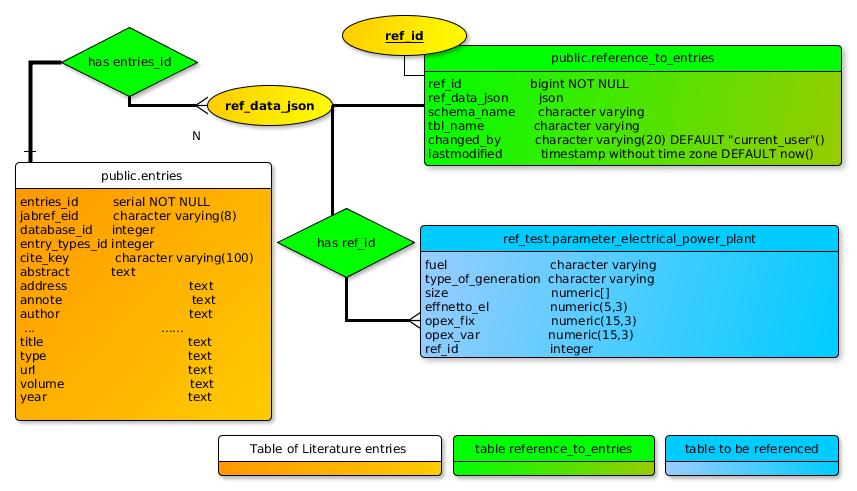
ERM references example
reference_to_entries table structure:
| ref_id
|
ref_data_json
|
schema_name
|
tbl_name
|
changed_by
|
lastmodified
|
| Reference ID
|
Json Documentation string
|
Name of the schema which includes the table “tbl_name”
|
Name of table with the data to be referenced
|
Name of user changing or creating this reference entry. (Automaticdefault setting)
|
Date of entry modification. (Automatic default setting)
|
Each row in the reference_to_entries table (green) contains a ref_data_json documentation string which links to the meta data in the Jabref table public.entries (orange).
Json documentation string structure on row:
Metadata Documentation of original data on rows
| Attribute (level 1)
|
Attribute (level 2)
|
Attribute (level 3)
|
Description
|
| Name
|
|
|
Name of the table to be referenced
|
| Discription
|
|
|
Short description of the table
|
| Column
|
|
|
Columns which need to be referenced
|
|
|
<column name 1>
|
|
Column name 1, (original column name and spelling)
|
|
|
jabref_entries_id
|
Jabref entries id of Literature entry
|
| Description
|
Short description
|
| <columnname2>
|
|
Column name 2, (original column name and spelling)
|
|
|
jabref_entries_id
|
Jabref entries id of Literature entry
|
| Description
|
Short description
|
| Note
|
|
|
Note or comment to this entry
|
Example:
Database table: ref_test.parameter_electrical_power_plant
| fuel
|
type_of_generation
|
effnetto_el
|
...
|
opex_var
|
ref_id
|
| coal
|
st
|
0.35
|
...
|
2
|
1
|
| ...
|
|
|
|
|
|
Database table: reference_to_entries table structure:
| ref_id
|
ref_data_json
|
schema_name
|
tbl_name
|
changed_by
|
lastmodified
|
| 1
|
{ "Name": "Collection of electrical power plant parameter", "Discription": "Technical parameter of confentional electrical power plants …
|
ref_test
|
parameter_electrical_power_plant
|
user_1
|
2016-03-17 15:37:24.538213
|
Jsonref_data_jsonExample:
{
"Name": ["Collection of electrical power plant parameter"],
"Description":["Technical parameter of conventional electrical power plants "],
"Column": [{
"effnetto_el":{"jabref_entries_id": 1,
"Description":"Electrical net efficiency},
"opex_var": {"jabref_entries_id": 2,
"Description":"Variable operational expenditure"} }],
"Note":["Short note or comment to this entry"]
}
|
Note: The general meta information like units are given meta documentation of the table.
The metadata BibTeX standard from JabRef is used for the Data Referencing in the table public.entries.
Processed and Result Data (calc/res)
The documentation rules for processed / calculated and results tables are equal the the original data.
As processed data does not necessarily have a simple source the fields "Source", "Original File", "Reference date" are commited. These information should be mentioned row-wise as explained in the next paragraph.
{"Name": "Results",
"Date of collection": ["01.08.2013"],
"Spatial resolution": ["Germany"],
"Description": ["Financial key figures of German municipalities (annual totals)",
"Regional level: municipalities, association of municipalities"],
"Column": [
{"Name":"id",
"Description":"Unique identifier,
"Unit":"" },
{"Name":"year",
"Description":"Reference Year",
"Unit":"" },
{"Name":"example_value",
"Description":"Some important value",
"Unit":"EUR" }],
"Changes":[
{ "Name":"Autor1",
"Mail":"Autor1@e-mail.com",
"Date":"16.06.2014",
"Comment":"Created table" },
{ "Name":"Autor2",
"Mail":"Autor2@e-mail.com",
"Date":"17.07.2014",
"Comment":"Translated field names"}],
"ToDo": ["Some datasets are odd -> Check numbers against another data"],
"Licence": ["Datenlizenz Deutschland – Namensnennung – Version 2.0 (dl-de/by-2-0;
[http://www.govdata.de/dl-de/by-2-0 http://www.govdata.de/dl-de/by-2-0])"],
"Instructions for proper use": ["Always state licence"]
"Label": ["Study", "Example Data"]
}
|
The comments on a row aim to enhance the reproducabilty of data that is present in the database by stating the underlying data that was used to compute this row as well as the applied computational methods.
During these processes some kinds of uncertainities might occur as well as the decissions (assumtions) that were made to deal with them. Examplatory, some values might be missing amid this row and a linear development during this period was assumed to fix this gap. Each row has to be annotated by a json dictionary that must contain the following fields:
- origin: Link or textual description of the data set this row origins from.
- method: Method used to calculate this row from above origin (e.g. Link to a python script)
- assumption: A list of dictionaries. Each dictionary describes an assumption and annotates the affected rows.
- begin: First column affected by the assumption
- end: Last column affected by the assumption
- type: Type of the problem that had to be solved. Each type requires one or more additional keys in this dictionary. Possible types and their required additional keys are:
- gap: A not all fields could be calculated and/or filled
- solution: Method that was used to generate date to fill this gap (e.g. linear interpolation)
- multiplicity: A field could be filled by several values
- solution: Method that was used to select one value (e.g. Minimum)
- values: Possible Values that could have been used
An examplatory dictionary:
{
"origin":"https://data.openmod-initiative.org/data/oedb/orig_db/table
"method":"https://github.com/openego/data_processing/blob/master/calc_ego_substation/Voronoi_ehv.sql"
"assumptions":
[
{
"type": "gap"
"begin": "step_15"
"end": "step_34"
"solution": "linear_interpolation"
}
]
}
|
